Background
So called “end-to-end” deep learning, as applied to ground vehicle autonomy, is an active field of research studied by many major companies. Current implementations focus on an attempt to leverage using human control of the vehicle as the primary mode of training supervision. While these attempts have been somewhat successful in very limited situations, such as highway driving on previously learned roads, this method results in a whole-scale abandonment of previously developed and understood techniques for controlling ground vehicles. This method of training limits the ability of the system to handle complicated maneuvering and is only able to handle unusual cases if the driver has previously handled a similar situation. This project is investigating the methods by which established autonomy system components can be utilized as part of a complete end-to-end convolutional neural network (CNN) based system.
Approach
Our approach has been to focus on using previously designed CNNs as components of a larger network. This network then provides the best quality data to the parts of the system for which CNNs are not well suited, such as control systems and longer-term planning. By starting with network components already well-trained on the individual problems, the overall optimization for the network starts from a state that is already well suited to the problem of controlling the vehicle. In addition, the network is responsible for learning the correct parameters to turn the observed classification data into an overall cost map, something that has, to date, depended on hand tuned values based on human intuition and experience rather than an optimization process. Existing maps collected by human drivers are used as ground truth for traversability and perception.
Accomplishments
We modified and evaluated different per-pixel segmentation approaches to detect drivable areas in both on- and off-road environments. We developed a network architecture that is both accurate at classifying and segmenting the environment in challenging lighting and environmental conditions, while still operating in real time. Using this information, we then projected the classification results into a 3D egocentric vehicle frame of reference. We then extended the deep learning network to learn road structure in three-dimensional space. Using this information, the system cannot only identify roads immediately around it, but also predict the presence of nearby roads from visual cues in the environment. This is similar to how humans can use experience and perception to infer the presence of nearby roads without directly observing them. In the future, this will potentially enable more aggressive exploration strategies for vehicles in un-mapped areas by enabling them to plan rewarding paths through areas they have not directly observed.
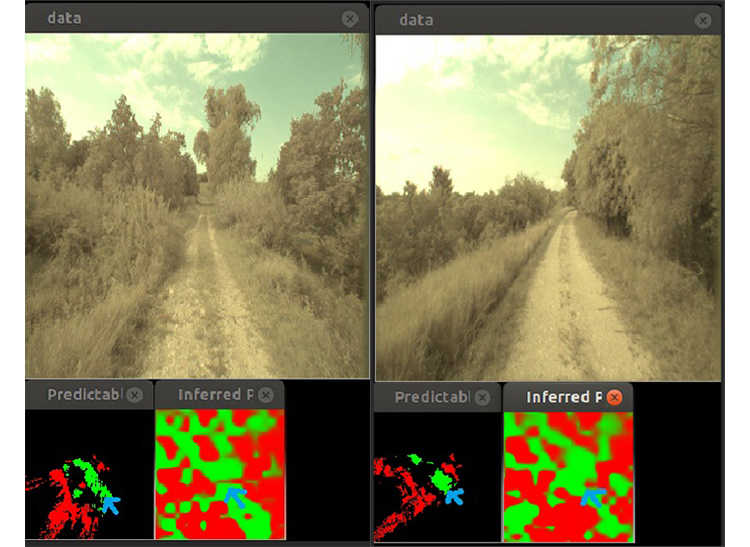
Figure 1: Costmap labels and network inference example 1 (left) show the perceived environment around the vehicle. Costmap labels and network inference example 2 (right) show the inferred environments produced by the network based on its learning of the environmental features.