Background
Southwest Research Institute® has developed a wide range of traffic management solutions for state and local governments across the country. The high human and economic toll of traffic accidents has made their mitigation an area of particular interest. Recent advances in machine learning (ML) and data-source availability have enabled the prediction of traffic accident probabilities, allowing preventative measures to be taken and faster responses to be made.
Approach
First, roadway data was gathered for the entire state of Texas and static features were extracted before information-preserving downsampling was performed. Next, dynamic data with one-hour temporal resolution was collected from a variety of sources, including weather, speed, and crowdsourced incident reports, covering the past year. The combined static and dynamic data were used as features in newly developed ML models, with the model output being a zero-to-one crash likelihood and “ground-truth” crash records being used as labels.
Accomplishments
Three ML models were developed to predict the likelihood of traffic accidents from the synthesis of spatiotemporal data. First, a static model – implemented as a message passing neural network (MPNN) – was developed using only roadway features and connectivity.
After the development of the static model, two dynamic models were produced. Due to difficulties in data collection, the speed information covered only the Austin area. Therefore, one model was produced covering the entire state but without speed, while the other included speed but covered only the Austin area. The same type of model was used for both – this was based on the MPNN developed for the static data but with an additional recurrent neural network to learn temporal patterns.
Figure 1 shows an overlay of downsampled roads colored and labelled with their predicted accident likelihood atop OpenStreetMap; at the time snapshot shown in Figure 1, a crash occurred as predicted by the high accident probability. In snapshot Figure 2, no accident occurred, and all predicted likelihoods are low. The static model had a mean absolute error (MAE) of 26% and false positive and negative rates of 17%. The first dynamic model (only Austin) had an MAE of 20%, a false positive rate of 2%, and a false negative rate of 12%; while the results for the second dynamic model (all of Texas) were 21%, 1%, and 19%, respectively.
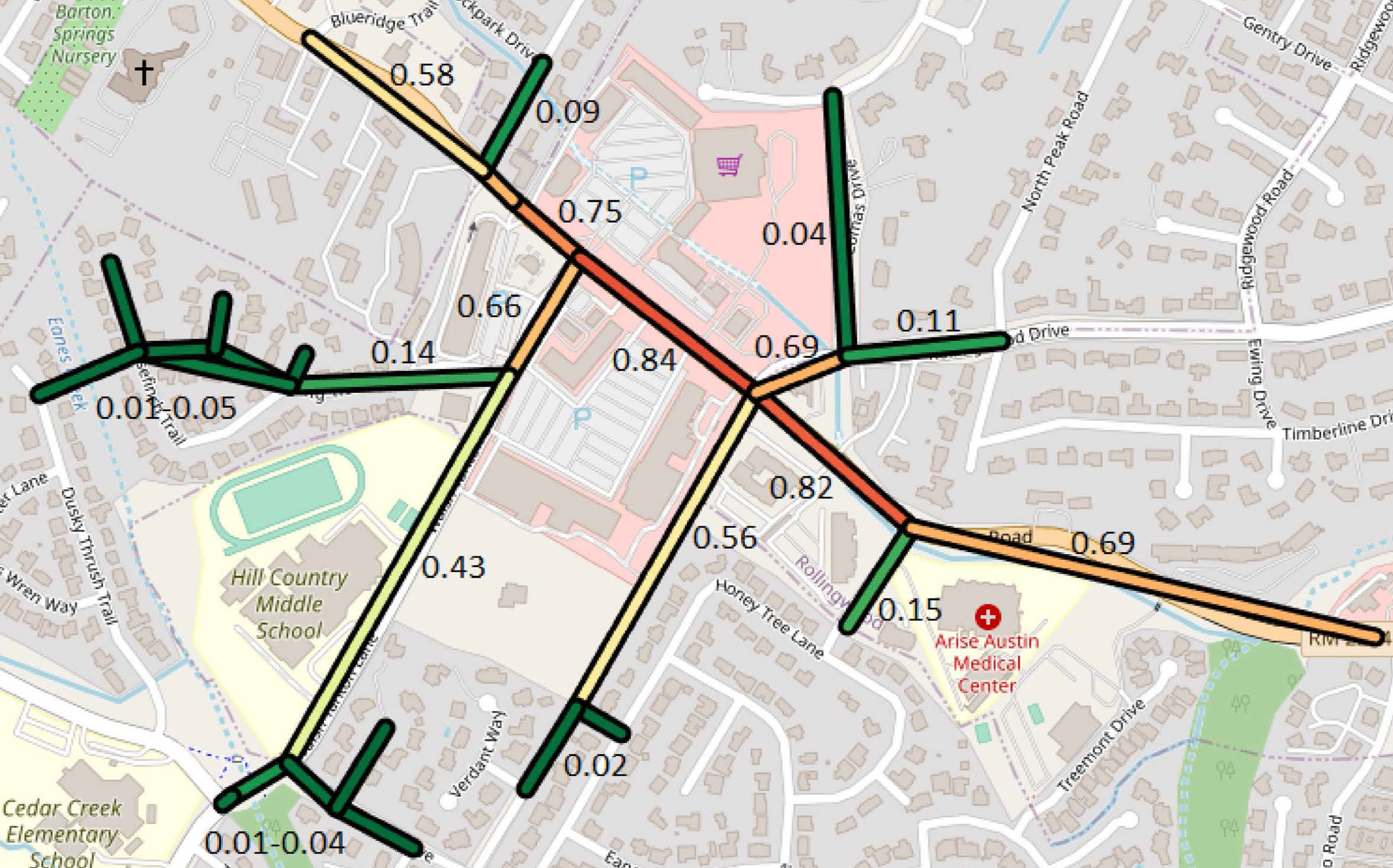
Figure 1: Crash probabilities for a location and time with an accident.
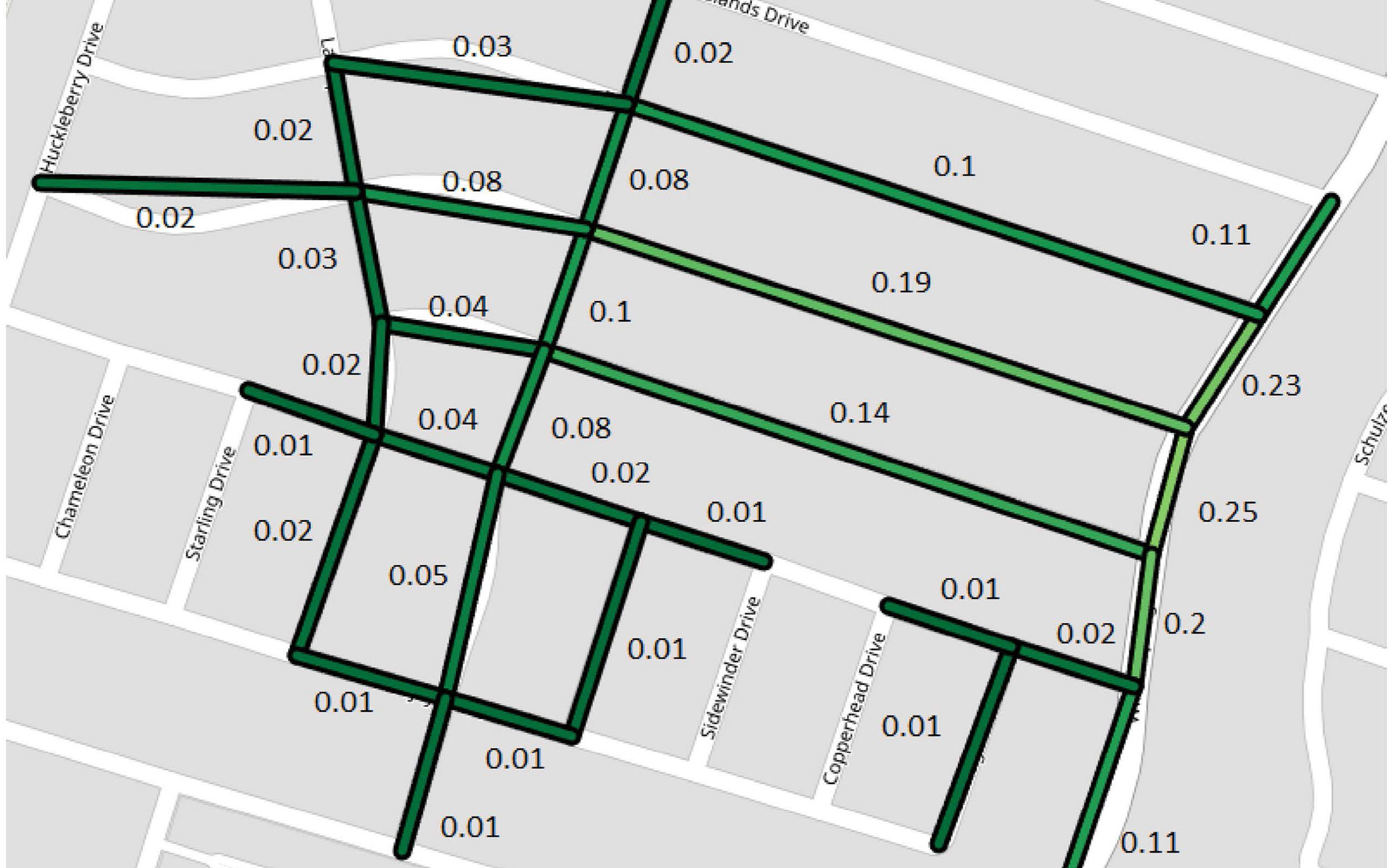
Figure 2: Crash probabilities for a location and time without an accident.