Background
In recent years, machine learning and artificial intelligence techniques have been used in both academia and industry to create Intelligent Learning Environments that provide support to move beyond problem solving and into teaching and improving skills. These technologies can allow for accelerated learning processes, offering adaptive, autonomous, and individualized feedback for trainees. Being able to accurately assess motions against an expert exemplar can be used to train athletic movements, human-robot Interaction, and fine motor skills. For this research, American Sign language (ASL) was chosen as a fine motor skill task with clearly defined goals and easily obtainable ground truth.
Approach
The initial steps of the system, both in development and deployment, were to capture data of a subject performing ASL signs and convert that to kinematic representations. First, the sign was captured using cameras and the captured motion was processed using a pose estimation model, a machine-learning model for identifying keypoints of the observed body, in this case the joints of both hands. The keypoints were then converted into a 3D representation using multi-view geometry or another machine learning model. From the 3D keypoints, an inverse kinematic optimization algorithm estimates the kinematic parameters (e.g., joint angles) of the hand. The set of these kinematic parameters in time constitutes the kinematic representation of a motion.
Using this process, a system was trained on video data of 4 human experts performing 25 selected signs which overlapped with two available datasets online. This combined dataset served as exemplar motions that were then encoded via one-shot learning embedding. During training, the embedding was tasked to solve an optimization to ensure that similar motions were grouped closely to each other in the embedding space while dissimilar motions were farther apart. The result was the ability to reduce the dimensionality of a kinematic representation of a motion to a smaller space.
When a trainee employed the system, their motions were mapped to the exemplar embedding space, and the nearest exemplar was found. The system then solved an optimization for the necessary modifications to the novice motion that would move it closer to the exemplar motion. The output of this was a kinematic representation that was communicated to the user with a 3D avatar. Figure 1 shows the overall workflow of this process.
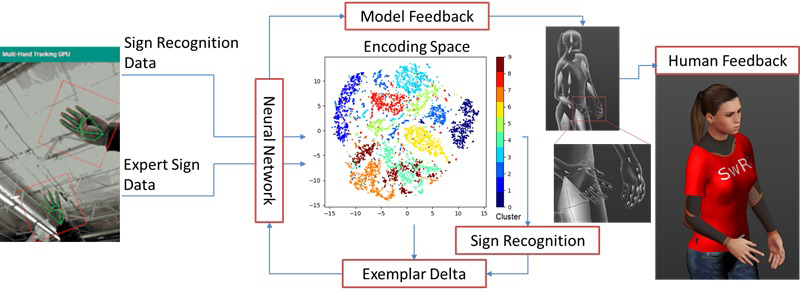
Figure 1: Generating Exemplar-Based Feedback Concept
Accomplishments
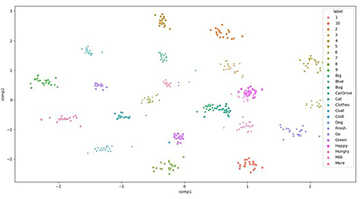
Figure 2: Scatter plot showing exemplars in learned 2D embedding.
Our learned feature embeddings, displayed in Figure 2, satisfy the desired properties of our encoding space. In most cases, classes are clearly separated as expected, and those groupings that are closer to each other do share many similarities. In general, we observed that the confused signs were often those which share similar hand shapes, which was expected given the way our system was representing data. While we did account for the rotation and translation of the hand in the capture space, we did not consider other information for context, such as the position of the signer’s face or body. To evaluate the accuracy of our classifier, we applied a k-Nearest Neighbor (kNN) classification. After producing confusion matrices, we found our kNN classifier established a 95.3% accuracy, exceeding our stated goal of 90% accuracy.