Background
Recently developed model-agnostic explanation methods are performed post-hoc. The most widely used approaches are based on feature relevance estimation via SHapley Additive exPlanations (SHAP). Runtime complexity is the main drawback of SHAP, as it scales exponentially with both the number of data instances and the number of input features. Model-specific and sampling techniques have been used to approximate full-scale SHAP at lower computational cost, but with loss of transferability and accuracy.
Approach
This research circumvents the limitations of post-hoc explanation methods by exploiting statistical information obtained at train-time to elucidate deep learning (DL) model behavior ante-hoc. Specifically, this research estimates feature relevance through perturbations in dataset subsamples derived by quasi-Monte Carlo simulation during cross-validation, a technique used in model selection and evaluation. We took four steps to prove the concept of model-agnostic ante-hoc model explanation. First, we generated data with known relative feature relevance from linear and nonlinear functions. Second, we implemented subsampling via quasi-Monte Carlo techniques during cross-validation. Third, we integrated feature relevance estimation with an open-source hyperparameter optimization framework. Finally, we evaluated the explanation methodology in terms of its impact on predictive and computational performance.
Accomplishments
The developed feature relevance estimation methods dramatically outperform SHAP in computation time and take less time than training the model (~60% of train time). They also have high explanation fidelity with a Pearson correlation coefficient of 0.82 with ground truth. The speed and fidelity of the sensitivity methods enable them to be used effectively in multiple folds of cross-validation. This information can be leveraged during model selection to identify hyperparameters that stabilize which patterns the model learns to satisfy its objective function. Further investigation is needed, but preliminary results suggest that incorporating explainability metrics into model selection may provide additional benefit in the form of regularization.
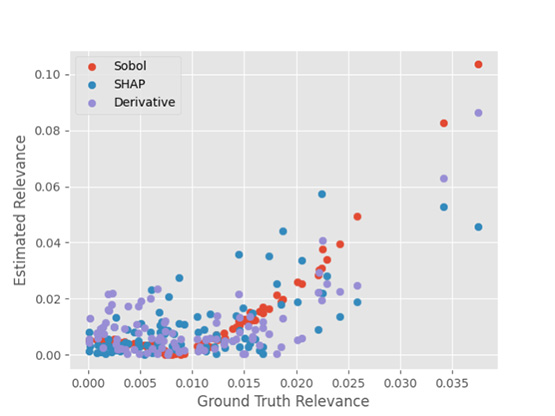
Figure 1: Comparison of deep learning explanation fidelity of sensitivity-based feature relevance estimation methods with state-of-the-art (SHAP).
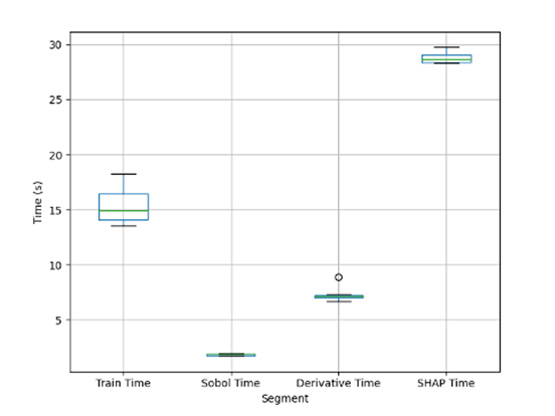
Figure 2: Comparison of runtime of sensitivity-based feature relevance estimation methods with state-of-the-art (SHAP).