Background
Southwest Research Institute’s® (SwRI®) Artificial Intelligence in Mass Spectroscopy (AIMS) group has worked to push the boundaries of non-targeted analysis (NTA) using gas- and liquid-chromatography coupled mass spectroscopy via SwRI’s “Lighthouse” suite of chemical analysis programs. These tools automate portions of the workflow, reducing the overall analysis time by 90%. With this increase in throughput, the review of identifications found during suspect screening becomes the new limiting factor. This research provides a novel data-driven method for quickly assigning chemical identification confidences and automates the processing of multi-mode source (MMS) data to further increase identification confidence.
Approach
To accelerate identification confidence assignment, a machine learning method consisting of three steps was created. First, a new structural similarity algorithm was developed using the National Institute of Standards and Technology (NIST) mass spectral library. A twin deep neural network was trained to predict the structural similarity between two compounds by taking in their mass spectra and outputting the predicted Tanimoto similarity. Next, a random forest was trained using 42,000 spectra with manually labelled confidence levels, the newly created structural similarity score, and other features to classify identifications into three categories based on Schymanski levels. Lastly, an algorithm was created to match MMS data to corresponding electron ionization (EI) peaks and reassess classifications based on this additional data.
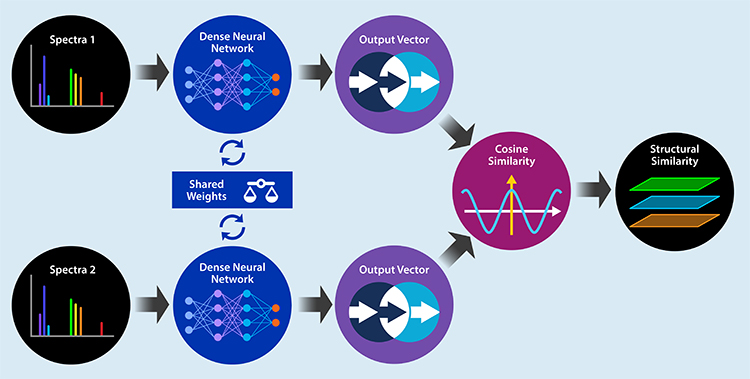
Figure 1: Deep Learning Similarity Score Model Architecture.
Accomplishments
When evaluated on a consumer products focused sample set consisting of 1,507 chemicals, the method developed during this research achieved 76% balanced class accuracy. This analysis was done in significantly less time compared to manual review, only taking 0.03 seconds per peak, compared to around two (2) minutes for manual review. Additionally, subcomponents of this research achieved notable performance with the deep learning-based structure similarity score producing significantly higher correlation to ground truth, with an R2 score of 0.92 compared to 0.3 using standard methods, and automated MMS matching algorithm obtaining an F1 score of 0.88.
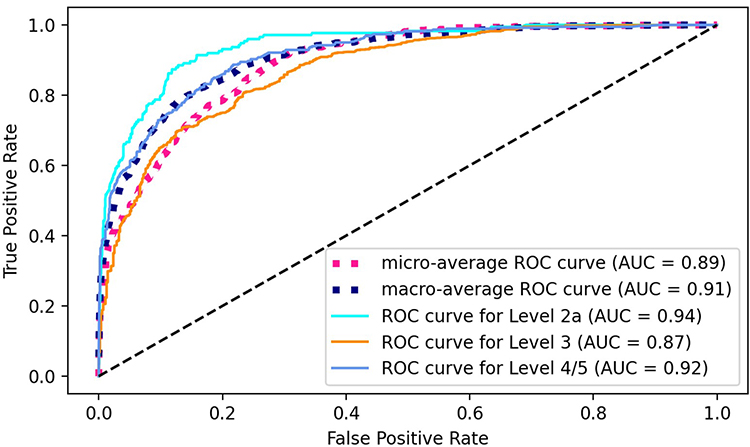
Figure 2: Identification Confidence Classifications Evaluated on Consumer Product Sample Set.