Background
The VORA project uses passive, vision-only sensors to generate a dense, robust world model for use in offroad navigation. This research is generating vision-based autonomy algorithms that are applicable to defense and surveillance autonomy, intelligent agricultural applications, and planetary exploration. Passive perception for world modeling enables stealth operation (since lidars can alert observers) and does not require more expensive or specialized sensors (e.g., radar or lidar), which makes it an appealing option for defense, agriculture, and space.
Approach
To achieve the goal of dense, robust world modeling for offroad navigation, three technical approaches were researched. These included deep learning stereo matching (DLSM), improved visual odometry using factor graph optimization, and a ground segmentation algorithm capable of effectively incorporating dense depth data. Ultimately, these three components were fed into SwRI’s existing World Model Lite software to produce highly accurate navigation costmaps. We performed testing on an SwRI-owned HMMWV 1165 at SwRI’s campus and in a high-fidelity modeling and simulation environment that was partially developed on a previous IR&D program.
Accomplishments
With notable improvements, we successfully got DLSM operating to provide information beyond what a typical stereo camera algorithm provides. The completed research from this effort has been integrated into a coherent perception pipeline and world model for Hound, SwRI’s offroad autonomy stack. The results will lessen or eliminate SwRI’s offroad autonomy software stack’s lidar dependency, which will position SwRI to meet the growing need for passive perception in space and defense applications.

Figure 1: From top left to bottom right: DLSM disparity map from RAFT-Stereo, a classical stereo matching result for comparison from the camera’s provided software; Rectified original left image from the camera; Raw confidence score logits; Normalized percentage confidence; and Softmax confidence.
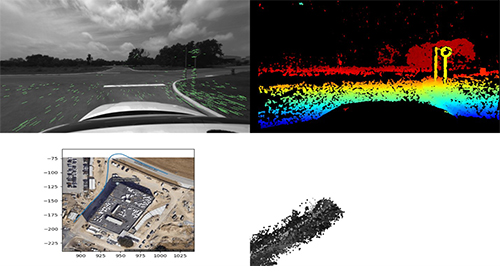
Figure 2: VSLAM Using Factor Graph Optimization. Keypoint Detection/Matching with subsequent frames (top left); Classical stereo matching disparity map generated from the left/right camera pair (top right); Estimated path around Building 299 (bottom left); Sparse volumetric point cloud being generated by VSLAM via triangulation and the sparse disparity (bottom right).