Background
Field Programmable Gate Arrays (FPGAs) are widely used in space applications due to their performance per watt characteristics and excellent radiation tolerance. Development times for FPGAs are significantly higher than those for Central Processing Units (CPUs) or Graphics Processing Units (GPUs). This research explores the development of a Computer Vision (CV) algorithm on an FPGA and evaluated the benefits of High Level Synthesis’ (HLS) potential to dramatically reduce development times for FPGAs.
Approach
The research team began by implementing the stereo vision pipeline shown in Figure 1 using HLS. This pipeline produces a disparity map from a pair of stereo images. The disparity map is computed using a local block matching algorithm. Since the images are rectified, the search for matching sections of filtered pixels must only be conducted in the horizontal dimension. This algorithm was implemented in HLS code, which is a thin layer on top of C++, and simulated in software. Following simulation, the application was synthesized for FPGA hardware and benchmarks were performed. Images used for benchmarks consisted of both open data sets and internal data captures possessed by Southwest Research Institute (SwRI). Computationally expensive pieces of the application were reimplemented in a Hardware Description Language (HDL) for comparison. The application was also duplicated on board the FPGA such that four (4) stereo pairs could be processed completely in parallel. This redundancy caused a small loss of throughput, down from 34 fps to 27 fps, however, the complete parallelization is a definitive advantage that FPGAs possess over CPU implementations of similar algorithms.
Accomplishments
The performance of HLS code that has been synthesized down to RTL code is more than adequate. Metrics for this application consisted of accuracy, throughput, and resource utilization. Results for these were 99% good pixels as compared to the CPU baseline, 34 frames per second (fps) with 1920x1080 pixel images, and the usage of less than 10% of FPGA resources, respectively. All these metrics were measured using the pure HLS implementation. While this research is far from exhaustive, it does indicate that HLS holds great potential for the efficient implementation of complex algorithms on board FPGAs. This holds significance for tightly constrained use cases. HLS holds many potential advantages for the future usage of FPGAs.
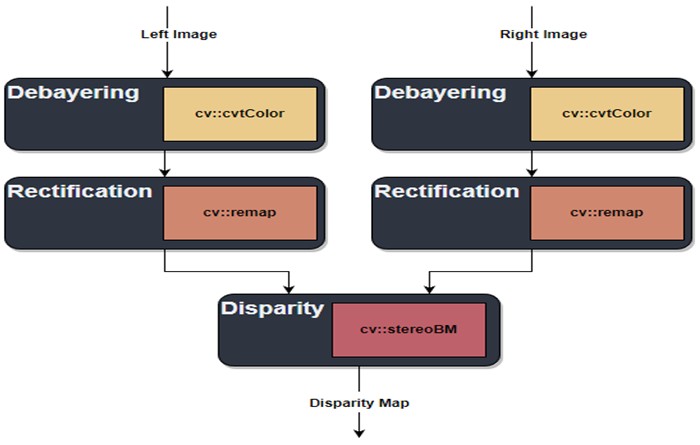
Figure 1: Stereo Vision Pipeline to produce a disparity map from left and right image pairs.