
Background
Recently, large language models (LLMs) have become increasingly popular in the field of machine learning due to their ability to generate text that is virtually indistinguishable from human communication. This research project aimed to develop a LLM interface to enable non-experts to interact with a complex engineering tool that traditionally requires expert domain knowledge to effectively use. The tool in focus predicts the risk of injury during Behind Armor Blunt Trauma (BABT) by sampling fast-running, AI-based surrogate models trained on simulation results from a high-fidelity human body finite element (FE) model. The FE model designed for various military applications is a part of the Incapacitation Prediction for Readiness in Expeditionary Domains – an Integrated Computational Tool (I-PREDICT) program. I-PREDICT calculates internal organ damage and injury probabilities at the tissue level, organ level using the Military Combat Incapacitation Score (MCIS), and whole-body level using the New Injury Severity Score (NISS). The LLM reliably parses user input and structures the model inputs necessary to execute pre-existing surrogate models for predicting injury risks, specifically for impacts to the liver, heart, and lower abdomen and removes the need for any FE modeling expertise.
Approach
We integrated an ‘Injury Assistant’ (IA) tool with I-PREDICT. The IA uses four LLMs to predict the risk of injury in a BABT scenario (Figure 1a). First, the Sensical LLM displays its capabilities and inquires if any of the scenarios accurately represent the user’s query, all in conversational terms. If a relevant scenario is identified, the Input Parser LLM is called, and it asks the user for pertinent information. The conversation persists until all the necessary information for injury risk calculation is gathered, while any irrelevant information is disregarded. Next, the Converter LLM takes pertinent prompts from the Input Parser LLM and calculates the injury metrics (Figure 1b, c). Finally, the MCIS LLM explains the injury metrics to the novice user in conversational terms.
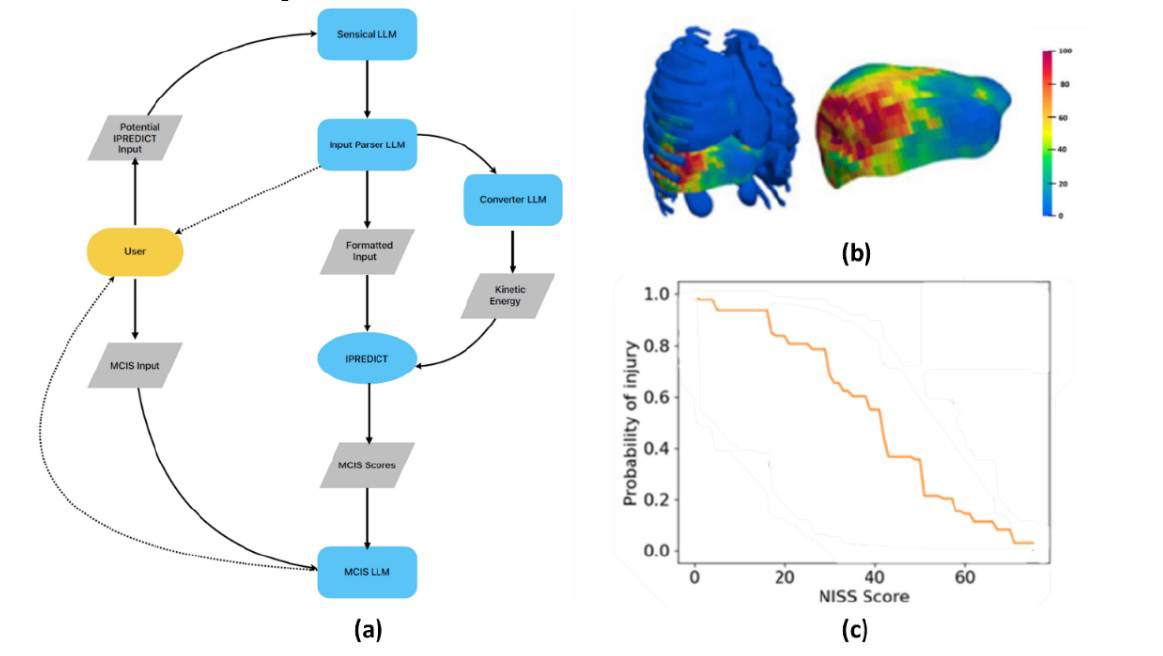
Figure 1: Figure (a) presents a flowchart illustrating the interactions between the LLM and the user. Dotted lines represent the conversation loop, while solid lines depict data flow. Blue boxes indicate processes managed by the LLM, whereas the yellow box highlights where user input is required. The blue circle represents the call to the I-PREDICT response surfaces, and all grey elements correspond to the data. Figure (b) shows the tissue probability of failure for organs of interest for a liver impact. Figure (c) shows the NISS-based injury risk curve for an impact at the liver.
Accomplishments
We successfully developed the IA, which can provide injury risk assessments for BABT scenarios. A key goal of the project was to ensure the IA delivers accurate results, with two primary success metrics: first, achieving at least 80% accuracy in extracting all relevant information from a regular conversation, and second, attaining a 90% success rate in cross-verifying results with an expert user of I-PREDICT. We exceeded both targets, achieving 100% accuracy in both metrics. Additionally, multiple users with various backgrounds across Southwest Research Institute (SwRI) tested the IA and provided positive feedback (Figure 2).

Figure 2: User Feedback Questionnaire on LLM Tool usage from 21 users across Southwest Research Institute.