
Background
In this internal research and development (IR&D) project, we aimed to improve automated object tracking and intelligent decision-making in surveillance style tasks. Current solutions may require expensive calibrations for full position reporting and can inundate users with overwhelming streams of data. Intelligent systems that make decisions based on automated object detection and tracking benefit from improved track quality and can make more intelligent decisions with more context.
Approach
We selected a multiview MOT dataset with highly overlapping cameras, including many labeled and unlabeled pedestrians. We used an open-source tool to generate a map and labeled it with user provided semantic data on top of reference satellite imagery, relying on visible landmarks to localize the cameras relative to a shared frame.
We created a standard detector object tracker that assigned detections to tracks. We predicted future track positions with naïve velocity estimation and track coasting when between sensor FOVs. We used class ontology and traits to improve tracking by constraining predictions based on inferred class capabilities, in this case, known reasonable pedestrian walking speeds. Finally, semantic reasoning allowed the world model to further constrain tracks/predictions and expectations by using knowledge of usual behaviors and class relationships relative to the environment. We incorporated additional semantic information to achieve higher-level predictions by predicting pedestrians will be forced to navigate around buildings and prefer to follow sidewalks.
Accomplishments
We loaded a priori information from open and internal sources to provide the world model with knowledge of the test environment, including rough camera positions, satellite imagery, and semantically labeled geometry in the test environment.

Figure 1: Seven simultaneous camera feeds showing a crowd of detected pedestrians.

Figure 2: A world model output visualization, showing the crowd of pedestrians being tracked. It shows both their current positions (green dots) and their position history (yellow dots).
The team created an architecture that can load, expand, and reason upon custom ontologies based on an existing, open reasoner. We connected this ontology server to the world model, granting access to the custom ontology and any logical conclusions that can be made from it. We developed a tracking system that fuses detections of pedestrians from multiple views into stable tracks using simple heuristics. We combined the world model’s basic tracking, a priori knowledge, and semantic reasoning to predict each pedestrian’s future state with biases and constraints.

Figure 3: Satellite imagery projected into a local topographic frame around the 7 cameras from Figure 1. Orange lines show loaded semantic data (sidewalks).
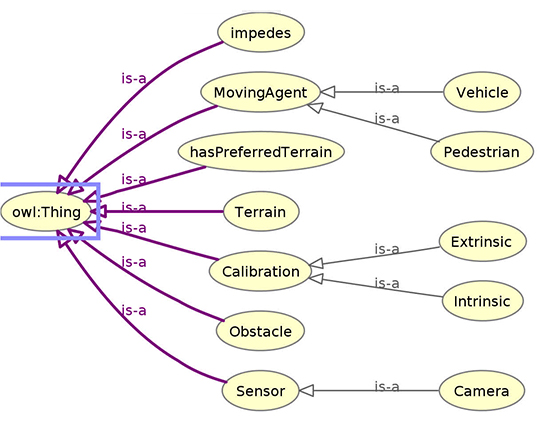
Figure 4: A simple ontology created to inform the world model about existing classes and expected behaviors when those classes interact.