
Background
Motion Planning is an integral component of all industrial robotics applications. SwRI’s robotics solutions typically utilize uses two types of motion planners to generate robot trajectories, search-based and gradient-based. Search based planners, such as the Open Motion Planning Library’s (OMPL) Rapidly Exploring Random Trees (RRT) algorithm, randomly explore the space of potential robot positions until it reaches the target position. These planners are great for solving easy problems but are infeasible for highly constrained problems. Gradient-base planners, such as Trajectory Optimization (TrajOpt), use a cost function and gradient descent to move the robot directly towards the goal. However, these planners are susceptible to getting stuck in local optima for problems where the robot must circumnavigate an obstacle, instead of moving directly towards the target. The objective of this project was to test the hypothesis that the Twin Delayed Deep Deterministic Policy Gradient (TD3) reinforcement learning algorithm can be used to solve highly constrained trajectories that require circumnavigating an obstacle.
Approach
This project required three major components to accomplish the goal of training a reinforcement learning algorithm to solve motion plans. The first component was developing an environment with a specifically targeted problem that would be difficult for traditional planners to solve. Next, the learning agent was setup so that it could explore this developed environment and generate data for training the neural networks. Finally, several hyperparameters were set up and tuned to encourage quick learning and convergence.
Accomplishments
A reinforcement learning motion planner was successfully trained to generate motion plans in a highly constrained environment. Two different collision geometries were trained on and the reinforcement learning motion planner was able to solve both with a 99.99% success rate. The obstacle was able to translate up to 5 cm in the x, y and z directions as well as rotate up to 10 degrees around each axis. It was found that the traditional motion planners were unable to solve for robot motions through these complex geometries.
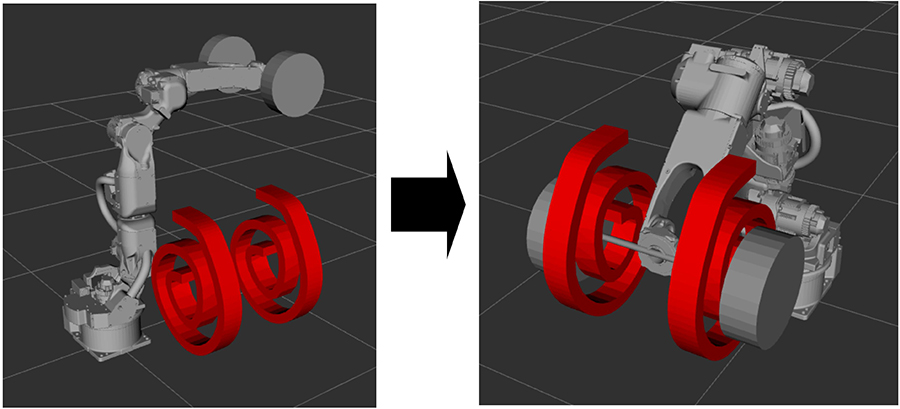
Figure 1: Motion plan goal with one of the geometries trained on.